Bonjour! Welcome to another part of the series on data visualization techniques. In the previous two articles, we discussed different data visualization techniques that can be applied to visualize and gather insights from categorical and continuous variables. You can check out the first two articles here:
In this article, we’ll go through the implementation and use of a bunch of data visualization techniques such as heat maps, surface plots, correlation plots, etc. We will also look at different techniques that can be used to visualize unstructured data such as images, text, etc.
### Importing the required libraries
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
import plotly.plotly as py
import plotly.graph_objs as go
Heatmaps
A heat map(or heatmap) is a two-dimensional graphical representation of the data which uses colour to represent data points on the graph. It is useful in understanding underlying relationships between data values that would be much harder to understand if presented numerically in a table/ matrix.
### We can create a heatmap by simply using the seaborn library.
sample_data = np.random.rand(8, 12)
ax = sns.heatmap(sample_data)
Fig 1. Heatmap using the seaborn library
Let’s understand this using an example. We’ll be using the metadata from Deep Learning 3 challenge. Link to the dataset. Deep Learning 3 challenged the participants to predict the attributes of animals by looking at their images.
### Training metadata contains the name of the image and the corresponding attributes associated with the animal in the image.
train = pd.read_csv('meta-data/train.csv')
train.head()
We will be analyzing how often an attribute occurs in relationship with the other attributes. To analyze this relationship, we will compute the co-occurrence matrix.
### Extracting the attributes
cols = list(train.columns)
cols.remove('Image_name')
attributes = np.array(train[cols])
print('There are {} attributes associated with {} images.'.format(attributes.shape[1],attributes.shape[0]))
Out: There are 85 attributes associated with 12,600 images.
# Normalizing the co-occurrence matrix, by converting the values into a matrix
# Compute the co-occurrence matrix in percentage
#Reference:https://stackoverflow.com/questions/20574257/constructing-a-co-occurrence-matrix-in-python-pandas/20574460
cooccurrence_matrix_diagonal = np.diagonal(cooccurrence_matrix)
with np.errstate(divide = 'ignore', invalid='ignore'):
cooccurrence_matrix_percentage = np.nan_to_num(np.true_divide(cooccurrence_matrix, cooccurrence_matrix_diagonal))
print('n Co-occurrence matrix percentage: n', cooccurrence_matrix_percentage)
We can see that the values in the co-occurrence matrix represent the occurrence of each attribute with the other attributes. Although the matrix contains all the information, it is visually hard to interpret and infer from the matrix. To counter this problem, we will use heat maps, which can help relate the co-occurrences graphically.
fig = plt.figure(figsize=(10, 10))
sns.set(style='white')
# Draw the heatmap with the mask and correct aspect ratio
ax = sns.heatmap(cooccurrence_matrix_percentage, cmap='viridis', center=0, square=True, linewidths=0.15, cbar_kws={"shrink": 0.5, "label": "Co-occurrence frequency"}, )
ax.set_title('Heatmap of the attributes')
ax.set_xlabel('Attributes')
ax.set_ylabel('Attributes')
plt.show()
Fig 2. Heatmap of the co-occurrence matrix indicating the frequency of occurrence of one attribute with other
Since the frequency of the co-occurrence is represented by a colour pallet, we can now easily interpret which attributes appear together the most. Thus, we can infer that these attributes are common to most of the animals.
Choropleth
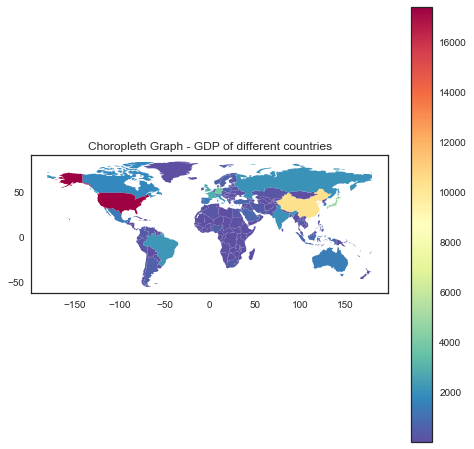
Choropleths are a type of map that provides an easy way to show how some quantity varies across a geographical area or show the level of variability within a region. A heat map is similar but doesn’t include geographical boundaries. Choropleth maps are also appropriate for indicating differences in the distribution of the data over an area, like ownership or use of land or type of forest cover, density information, etc. We will be using the geopandas library to implement the choropleth graph.
We will be using choropleth graph to visualize the GDP across the globe. Link to the dataset.
# Importing the required libraries
import geopandas as gpd
from shapely.geometry import Point
from matplotlib import cm
# GDP mapped to the corresponding country and their acronyms
df =pd.read_csv('GDP.csv')
df.head()
COUNTRY
GDP (BILLIONS)
CODE
0
Afghanistan
21.71
AFG
1
Albania
13.40
ALB
2
Algeria
227.80
DZA
3
American Samoa
0.75
ASM
4
Andorra
4.80
AND
### Importing the geometry locations of each country on the world map
geo = gpd.read_file(gpd.datasets.get_path('naturalearth_lowres'))[['iso_a3', 'geometry']]
geo.columns = ['CODE', 'Geometry']
geo.head()
# Mapping the country codes to the geometry locations
df = pd.merge(df, geo, left_on='CODE', right_on='CODE', how='inner')
#converting the dataframe to geo-dataframe
geometry = df['Geometry']
df.drop(['Geometry'], axis=1, inplace=True)
crs = {'init':'epsg:4326'}
geo_gdp = gpd.GeoDataFrame(df, crs=crs, geometry=geometry)
## Plotting the choropleth
cpleth = geo_gdp.plot(column='GDP (BILLIONS)', cmap=cm.Spectral_r, legend=True, figsize=(8,8))
cpleth.set_title('Choropleth Graph - GDP of different countries')
Fig 3. Choropleth graph indicating the GDP according to geographical locations
Surface plot
Surface plots are used for the three-dimensional representation of the data. Rather than showing individual data points, surface plots show a functional relationship between a dependent variable (Z) and two independent variables (X and Y).
It is useful in analyzing relationships between the dependent and the independent variables and thus helps in establishing desirable responses and operating conditions.
from mpl_toolkits.mplot3d import Axes3D
from matplotlib.ticker import LinearLocator, FormatStrFormatter
# Creating a figure
# projection = '3d' enables the third dimension during plot
fig = plt.figure(figsize=(10,8))
ax = fig.gca(projection='3d')
# Initialize data
X = np.arange(-5,5,0.25)
Y = np.arange(-5,5,0.25)
# Creating a meshgrid
X, Y = np.meshgrid(X, Y)
R = np.sqrt(np.abs(X**2 - Y**2))
Z = np.exp(R)
# plot the surface
surf = ax.plot_surface(X, Y, Z, cmap=cm.GnBu, antialiased=False)
# Customize the z axis.
ax.zaxis.set_major_locator(LinearLocator(10))
ax.zaxis.set_major_formatter(FormatStrFormatter('%.02f'))
ax.set_title('Surface Plot')
# Add a color bar which maps values to colors.
fig.colorbar(surf, shrink=0.5, aspect=5)
plt.show()
One of the main applications of surface plots in machine learning or data science is the analysis of the loss function. From a surface plot, we can analyze how the hyperparameters affect the loss function and thus help prevent overfitting of the model.
Fig 4. Surface plot visualizing the dependent variable w.r.t the independent variables in 3-dimensions
Visualizing high-dimensional datasets
Dimensionality refers to the number of attributes present in the dataset. For example, consumer-retail datasets can have a vast amount of variables (e.g. sales, promos, products, open, etc.). As a result, visually exploring the dataset to find potential correlations between variables becomes extremely challenging.
Therefore, we use a technique called dimensionality reduction to visualize higher dimensional datasets. Here, we will focus on two such techniques :
Before we jump into understanding PCA, let’s review some terms:
Variance: Variance is simply the measure of the spread or extent of the data. Mathematically, it is the average squared deviation from the mean position.
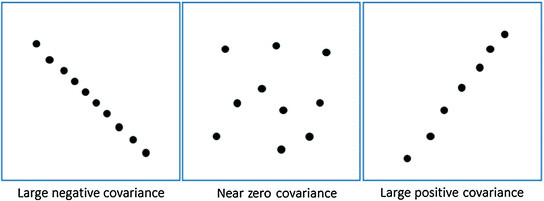
Covariance: Covariance is the measure of the extent to which corresponding elements from two sets of ordered data move in the same direction. It is the measure of how two random variables vary together. It is similar to variance, but where variance tells you the extent of one variable, covariance tells you the extent to which the two variables vary together. Mathematically, it is defined as:
A positive covariance means X and Y are positively related, i.e., if X increases, Y increases, while negative covariance means the opposite relation. However, zero variance means X and Y are not related.
Fig 5. Different types of covariance
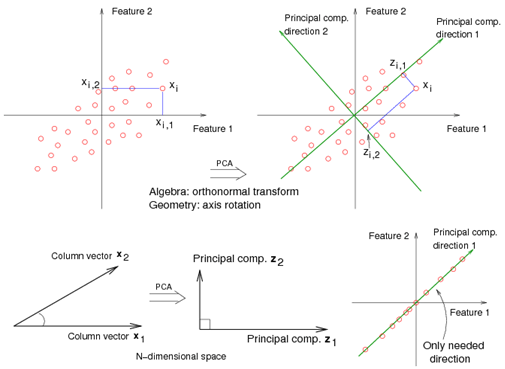
PCA is the orthogonal projection of data onto a lower-dimension linear space that maximizes variance (green line) of the projected data and minimizes the mean squared distance between the data point and the projects (blue line). The variance describes the direction of maximum information while the mean squared distance describes the information lost during projection of the data onto the lower dimension.
Thus, given a set of data points in a d-dimensional space, PCA projects these points onto a lower dimensional space while preserving as much information as possible.
Fig 6. Illustration of principal component analysis
In the figure, the component along the direction of maximum variance is defined as the first principal axis. Similarly, the component along the direction of second maximum variance is defined as the second principal component, and so on. These principal components are referred to the new dimensions carrying the maximum information.
# We will use the breast cancer dataset as an example
# The dataset is a binary classification dataset
# Importing the dataset
from sklearn.datasets import load_breast_cancer
data = load_breast_cancer()
X = pd.DataFrame(data=data.data, columns=data.feature_names) # Features
y = data.target # Target variable
# Importing PCA function
from sklearn.decomposition import PCA
pca = PCA(n_components=2) # n_components = number of principal components to generate
# Generating pca components from the data
pca_result = pca.fit_transform(X)
print("Explained variance ratio : n",pca.explained_variance_ratio_)
Out: Explained variance ratio :
[0.98204467 0.01617649]
We can see that 98% (approx) variance of the data is along the first principal component, while the second component only expresses 1.6% (approx) of the data.
# Creating a figure
fig = plt.figure(1, figsize=(10, 10))
# Enabling 3-dimensional projection
ax = fig.gca(projection='3d')
for i, name in enumerate(data.target_names):
ax.text3D(np.std(pca_result[:, 0][y==i])-i*500 ,np.std(pca_result[:, 1][y==i]),0,s=name, horizontalalignment='center', bbox=dict(alpha=.5, edgecolor='w', facecolor='w'))
# Plotting the PCA components
ax.scatter(pca_result[:,0], pca_result[:, 1], c=y, cmap = plt.cm.Spectral,s=20, label=data.target_names)
plt.show()
Fig 7. Visualizing the distribution of cancer across the data
Thus, with the help of PCA, we can get a visual perception of how the labels are distributed across given data (see Figure).
T-distributed Stochastic Neighbour Embeddings (t-SNE) is a non-linear dimensionality reduction technique that is well suited for visualization of high-dimensional data. It was developed by Laurens van der Maten and Geoffrey Hinton. In contrast to PCA, which is a mathematical technique, t-SNE adopts a probabilistic approach.
PCA can be used for capturing the global structure of the high-dimensional data but fails to describe the local structure within the data. Whereas, “t-SNE” is capable of capturing the local structure of the high-dimensional data very well while also revealing global structure such as the presence of clusters at several scales. t-SNE converts the similarity between data points to joint probabilities and tries to maximize the Kullback-Leibler divergence between the joint probabilities of the low-dimensional embeddings and high-dimension data. In doing so, it preserves the original structure of the data.
# We will be using the scikit learn library to implement t-SNE
# Importing the t-SNE library
from sklearn.manifold import TSNE
# We will be using the iris dataset for this example
from sklearn.datasets import load_iris
# Loading the iris dataset
data = load_iris()
# Extracting the features
X = data.data
# Extracting the labels
y = data.target
# There are four features in the iris dataset with three different labels.
print('Features in iris data:n', data.feature_names)
print('Labels in iris data:n', data.target_names)
Out: Features in iris data:
['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)', 'petal width (cm)']
Labels in iris data:
['setosa' 'versicolor' 'virginica']
# Loading the TSNE model
# n_components = number of resultant components
# n_iter = Maximum number of iterations for the optimization.
tsne_model = TSNE(n_components=3, n_iter=2500, random_state=47)
# Generating new components
new_values = tsne_model.fit_transform(X)
labels = data.target_names
# Plotting the new dimensions/ components
fig = plt.figure(figsize=(5, 5))
ax = Axes3D(fig, rect=[0, 0, .95, 1], elev=48, azim=134)
for label, name in enumerate(labels):
ax.text3D(new_values[y==label, 0].mean(),
new_values[y==label, 1].mean() + 1.5,
new_values[y==label, 2].mean(), name,
horizontalalignment='center',
bbox=dict(alpha=.5, edgecolor='w', facecolor='w'))
ax.scatter(new_values[:,0], new_values[:,1], new_values[:,2], c=y)
ax.set_title('High-Dimension data visualization using t-SNE', loc='right')
plt.show()
Fig 8. Visualizing the feature space of the iris dataset using t-SNE
Thus, by reducing the dimensions using t-SNE, we can visualize the distribution of the labels over the feature space. We can see that in the figure the labels are clustered in their own little group. So, if we’re to use a clustering algorithm to generate clusters using the new features/components, we can accurately assign new points to a label.
Conclusion
Let’s quickly summarize the topics we covered. We started with the generation of heatmaps using random numbers and extended its application to a real-world example. Next, we implemented choropleth graphs to visualize the data points with respect to geographical locations. We moved on to implement surface plots to get an idea of how we can visualize the data in a three-dimensional surface. Finally, we used two- dimensional reduction techniques, PCA and t-SNE, to visualize high-dimensional datasets.
I encourage you to implement the examples described in this article to get a hands-on experience. Hope you enjoyed the article. Do let me know if you have any feedback, suggestions, or thoughts on this article in the comments below!
Extremely technically proficient and a highly imaginative Lead UI/UX Developer responsible for the development of multiple successful digital campaigns for several international companies and agencies. Demonstratable record of achievement developing highly successful ecommerce websites from initial UI/UX development, straight through to launch. Fully experienced front-end developer with amazing project and product management skills. Strong expertise in rapid prototyping of sites and their subsequent development using either custom HTML5/PHP or CMS solutions. An innate ability to communicate complex workflows to non-technical and technical stakeholders alike ensures smooth communications across projects and personnel. Also, active Professional Member of British Computer Society.